Zarządzanie wydaniami aplikacji - Git workflow
Nieodłącznym elementem naszej ciężkiej, programistycznej pracy jest wgrywanie ukończonych zadań na serwery testowe/przedprodukcyjne, a w końcu na produkcję. Jeśli jesteśmy szczęściarzami, to zadanie po przejściu etapu testów po stronie klienta trafia jak najszybciej na staging a następnie prosto na produkcję. W takim przypadku zarządzanie wydaniami sprowadza się do uaktualniania gałęzi odpowiadających stanom poszczególnych serwerów, np. "develop", "staging" i "production". Niestety, w swojej praktyce często spotykałem sytuację, gdy klient zmieniał zdanie co do kolejności wypuszczania kolejnych zadań. Z dnia na dzień. Z serwera na serwer. Zbiór zadań znajdujących się na serwerze testowym był znacząco różny od zbioru zadań z przedprodukcji. Ten z kolei różnił się od ostatecznej wersji tego, co powinno zostać wgrane na produkcję.
To właśnie z potrzeby bezkonfliktowej współpracy w takich warunkach zrodził się proponowany przeze mnie schemat zarządzania wydaniami. Ma on swoją reprezentację w odpowiedniej organizacji gałęzi w systemie kontroli wersji, w naszym przypadku będzie to git.
Zarządzanie wydaniami w praktyce
Dzisiejszy wpis jest zapiskiem zarządzania gałęziami dla standardowego zadania (nazwijmy je "task 1") przy zachowaniu opisanych powyżej założeń:
- w każdej chwili chcemy mieć możliwość wgrania dowolnego zadania na serwer testowy (i tylko jego)
- przygotowując wgrywkę (ang. deploy) na serwer przedprodukcyjny chcemy mieć możliwość wyboru dowolnego zbioru zadań przetestowanych na serwerze testowym
- to samo co powyżej dotyczy przygotowania wgrywki na serwer produkcyjny
Od początku - tworzymy gałąź dla zadania!
Zakładamy, że główną gałęzią, odzwierciedlającą stan serwera produkcyjnego (ang. live) jest gałąź master. W tym scenariuszu tworzymy nową gałąź dla zadania (nazwijmy ją task_1), wychodzącą z gałęzi master:
$ git checkout master
$ git pull
$ git checkout -b task_1
Ważne jest, aby uaktualnić lokalny stan gałęzi master, najprościej zrobić to poprzez wydanie polecenia "git pull". Dzięki temu mamy pewność, że pracujemy na aktualnej wersji kodu napędzającej produkcję.
Praca nad zadaniem
Od tej pory możemy pracować spokojnie nad zadaniem task_1. W razie potrzeby rozpoczęcia prac nad kolejnym zadaniem powtarzamy procedurę, tworząc nową gałąź i wychodząc ponownie z master'a. Warto w tym miejscu zaznaczyć, że nie należy traktować gita jako narzędzia do archiwizacji wersji kodu "co jakiś czas", "po skończeniu zadania" czy "na koniec dnia". Róbmy commity często, zawierajmy w nich niewielkie, spójne zmiany kodu oraz opatrzmy je krótkim, jasnym komentarzem. Jest to bardzo pomocne w przypadku, gdy zmiany z naszego zadania powodują powstanie błędów regresyjnych. Niewielkie, dobrze opisane commity pomogą odnaleźć dokładną wersję kodu powodującą powstanie błędu. Łatwiejsze będzie także zrozumienie przyczyny jego powstania i jej usunięcie.
Wgrywka na serwer testowy (opcjonalnie)
Sprawdzonym przeze mnie schematem jest utrzymywanie serwera testowego, na którym klienci mogą testować nasze zadania. Serwer taki z założenia służy do testowania jednego zadania "na raz". Ma to znaczenie, ponieważ chcemy mieć maksymalną dowolność w doborze zadań, mających być następnie wgranymi na serwer przedprodukcyjny. Nie chcemy po prostu mergować ich do wspólnej gałęzi, tak, aby pozostały niezależne od siebie. Wadą jest oczywiście to, że serwer taki odzwierciedla w danej chwili jedynie stan produkcji + maksymalnie jednego nowego zadania. Z praktyki wiem jednak też, że nie jest to duża wada, szczególnie jeśli skonfigurujemy narzędzie CD (ang. Continous Delivery). Można zrobić to za pomocą np. Jenkinsa, zewnętrznego serwisu (Travis CI, Codeship, Circle CI) bądź własnych skryptów, umożliwiając wgrywanie zmian w ciągu kilku minut. Ważne jest, aby nie mergować takich zadań do żadnej wspólnej gałęzi. Wgrywanie zmian na serwer testowy powinno odbywać się poprzez wybór gałęzi z zadaniem (czyli np. task_1 lub task_2).
Pozostaje kwestia ograniczenia dostępu do takiego serwera, o czym napisałem kilka słów w osobnym wpisie.
Przygotowanie wgrywki na serwer przedprodukcyjny
Aby przygotować wgrywkę na serwer przedprodukcyjny korzystamy z dedykowanej gałęzi, w naszym przykładzie nazwanej rc_1. Takich gałęzi, służących do wgrywania zmian na serwer przedprodukcyjny może być więcej w razie potrzeby. Osobiście, standardowo nazywam je rc_2, rc_3 itd. Są one przydatne w sytuacji, gdy na staging wgrano np. zmiany składające się na zadania 1, 2 i 3, po czym klient chce wgrać na produkcję tylko zadania 1 i 3. W takim przypadku tworzymy np. na gałęzi rc_2 (zawsze wychodzącej z aktualnego stanu gałęzi podstawowej, master!) nowy release, składający się tylko z zadań 1 i 3. Więcej o takim przypadku napisałem w kolejnym punkcie tego wpisu.
Przygotowanie wgrywki na serwer przedprodukcyjny sprowadza się do zmergowania zadań, które mają się w nim znaleźć do odpowiedniej gałęzi (najczęściej rc_1). Wgrywany na serwer jest aktualny stan wybranej gałęzi rc_*. Na tym etapie możemy dobrać dowolne spośród gotowych zadań.
Testowanie na serwerze przedprodukcyjnym
Wgrywanie zmian na produkcję musi być poprzedzone przetestowaniem ich na serwerze przedprodukcyjnym. Najlepiej aby zajął się tym profesjonalny tester manualny. Świetnie sprawdzają się napisane specjalnie do tego celu testy automatyczne (end-to-end). Do ich stworzenia polecić mogę np. narzędzie cypress.
Klient zmienił zdanie! Mamy wgrać na produkcję inny zbiór zadań...
Czasami zdarza się, że priorytet jednego z zadań/część zadań wgranych na serwer przedprodukcyjny ulega zwiększeniu. Powinniśmy w takim wypadku wgrać je na produkcję jak najszybciej. Dla przykładu, wgrano na serwer przedprodukcyjny zadania 1, 2 oraz 3. Teraz jednak na produkcję powinny zostać wgrane tylko zadania 1 i 3. Prawidłowym postępowaniem w takiej sytuacji jest przygotowanie nowego release'u np. na gałęzi rc_2, zawierającego tylko zadania 1 i 3 (uzyskały większy priorytet), dokonanie wgrywki na serwer przedprodukcyjny z gałęzi rc_2 i testowanie.
Dlaczegóżby jednak nie wgrać od razu na produkcję zadań 1 i 3, szczególnie jeśli zostały już przetestowane?
Po pierwsze, nie chcemy przenosić na gałąź master zmian ręcznie, commit po commicie wybranych zadań. Musielibyśmy to zrobić, ponieważ gałąź rc_1 zawiera zmiany także z zadania 2, które jednak nie powinno znaleźć się teraz na produkcji. Można to zrobić np. za pomocą komendy git cherry-pick, jest to jednak sposób długotrwały i podatny na błędy.
Po drugie, zadania 1 i 3 mogą być zależne zadania 2, które teraz należy pominąć. Możliwa jest więc sytuacja, w której wgrane razem zadania 1, 2 i 3 działają bez zarzutu, jednak bez zadania 2. pojawiają się błędy. Ważne jest więc, aby na produkcję wgrywać tylko stan kodu, który był już wcześniej sprawdzony na serwerze przedprodukcyjnym. Wgranie tylko zadań 1 i 3 w naszym przykładzie byłoby błędem. Jest tak dlatego, że sprawdzone zostało tylko działanie ich razem z zadaniem 2. Nie oznacza to automatycznie, że również bez niego wszystko będzie działać poprawnie.
Wgrywka na produkcję
Ostatnim etapem jest wgranie zmian na produkcję, którego dokonujemy na żądanie klienta oraz, powtórzę raz jeszcze, tylko po wcześniejszym przetestowaniu identycznej wersji kodu na serwerze przedprodukcyjnym. Rozpoczynamy oczywiście od zmergowania gałęzi zawierającej wersję kodu testowaną na serwerze przedprodukcyjnym (np. rc_1) do gałęzi master. Następnie proponuję tagowanie wersji na gałęzi master, tak, aby kolejne release'y kodu były uporządkowane, ponumerowane i odpowiednio opisane. Do stworzenia tagów w Gicie służy komenda:
$ git tag -a v0.1 -m 'Minimal Valueable Product'
Natomiast aby wgrać je do zdalnego repozytorium możemy posłużyć się komendą:
$ git push origin v0.1
Narzędzie służące do przygotowania wgrywki na produkcję powinno akceptować nazwę tagu jako parametr. Dzięki temu wgrywane będą tylko przygotowane w tym celu, odpowiednie wersje kodu.
Zarządzanie wydaniami na konkretnym przykładzie
Pokażę jeszcze przykład zarządzania wydaniami na przykładzie 4 zadań, 2 wgrywek na serwer przedprodukcyjny i 2 wgrywek na produkcję. Sytuację przedstawia poniższy schemat:
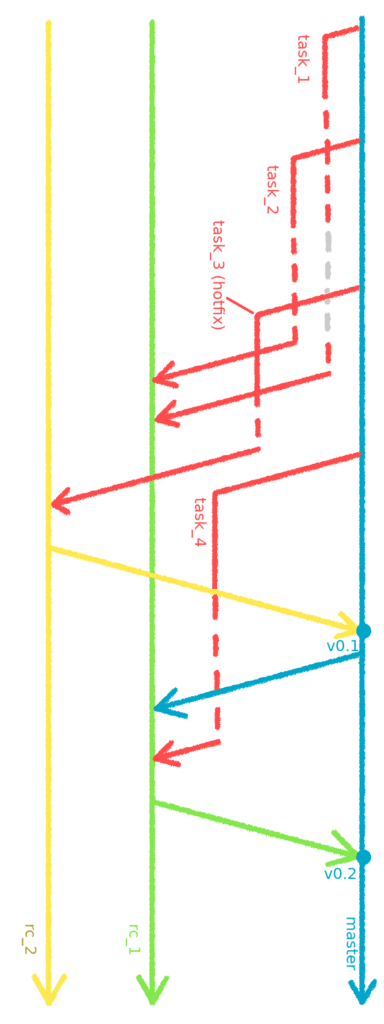 Przykładowa historia prac nad zadaniami i zarządzania ich gałęziami
Przykładowa historia prac nad zadaniami i zarządzania ich gałęziami
Gałęzie rc_1 i rc_2 służą do przygotowania wgrywek na przedprodukcyjny serwer, gałąź master odzwierciedla stan kodu na produkcji, gałęzie z zadaniami nazywają się task_1, task_2, task_3 i task_4. Linia przerywana czerwona oznacza okres testowania zadania na serwerze testowym. Linia przerywana szara oznacza, że zadanie jest gotowe, ale aktualnie nie jest wgrane na serwer testowy. Jak pamiętamy, może na nim być jednocześnie wgrane tylko 1 zadanie.
Analiza krok po kroku
Rozpoczęto pracę nad zadaniem task_1 (wychodząc nową gałęzią z master'a), ukończono pracę i wgrano na serwer testowy. W międzyczasie rozpoczęto pracę nad kolejnym zadaniem (task_2). Po ukończeniu pracy zostało ono wgrane na serwer testowy (zamiast zadania task_1 - linia przerywana szara). W trakcie gdy na serwerze testowym znajdowało się zadanie task_2, rozpoczęto pracę nad priorytetowym zadaniem task_3 (hotfix). Zadania task_1 i task_2 zostały zmergowane do gałęzi rc_1. Po zakończeniu prac nad zadaniem task_3 i przetestowaniu go na serwerze testowym zmergowano go do gałęzi rc_2. Zrobiono tak, ponieważ zadanie to powinno znaleźć się na produkcji jak najszybciej, bez czekania na przetestowanie i ewentualne poprawki do zadań task_1 i task_2. Z gałęzi rc_2 wgrano kod na serwer przedprodukcyjny, przetestowano go i zmergowano do gałęzi master. Następnie stworzono nowy tag v0.1 i wgrano kod na produkcję.
Dalej, zmiany z gałęzi master zostały włączone do gałęzi rc_1 z zadaniami task_1 i task_2 (ważne!). Po przetestowaniu, zmergowano gałąź rc_1 do master, stworzono nowy tag v0.2 i wgrano kod na produkcję.
Na dzisiaj to już wszystko, mam nadzieję, że przedstawiłem jasno proponowany przeze mnie schemat zarządzania wydaniami aplikacji w praktyce. Oraz że komuś z Was się on przyda w codziennej pracy. A może macie lepsze/inne sprawdzone schematy zarządzania gałęziami i wgrywkami? Zapraszam do dyskusji w komentarzach!