Ciągła integracja w kontekście testów aplikacji i Jenkinsa
Ciągła integracja (ang. continuous integration, CI) jest procesem mającym na celu zapewnienie, że wprowadzając do projektu jakiekolwiek zmiany spełnia on wciąż wszystkie wymagania funkcjonalne, jest integralny. Proces ten automatyzuje różne kroki mające na celu zapewnienie tej integralności, najczęściej są to:
- uruchomienie testów aplikacji (jednostkowe, integracyjne, end-to-end itd.) przy każdej nowej zmianie wchodzącej do repozytorium
- próba zbudowania nowej wersji aplikacji, z wprowadzonymi zmianami
- aktualizacja dokumentacji technicznej, jeśli taka istnieje
Dzisiejszy wpis opisuje w jaki sposób rozpocząć wdrażanie ciągłej integracji korzystając z popularnego serwera CI, jakim jest Jenkins.
Ciągła integracja na przykładzie projektu z Bitbucket’a
Rozpoczniemy od stworzenia nowego projektu w Jenkinsie, w którym zostanie skonfigurowane automatyczne uruchamianie testów aplikacji. Zakładamy tutaj, że kod tej aplikacji hostowany jest w serwisie Bitbucket.
Tworzymy nowy projekt w Jenkinsie
Zaczynamy od stworzenia nowego projektu, w tym celu klikamy “Nowy Projekt” w lewym panelu:
 Lewy panel administracyjny Jenkinsa
Lewy panel administracyjny Jenkinsa
Przejdziemy do nowego ekranu, w którym możemy wpisać nazwę dla projektu (w tym przykładzie “awesome-app-ci”). Wybieramy “Ogólny projekt” i klikamy “OK”:
 Widok tworzenia nowego projektu w Jenkinsie
Widok tworzenia nowego projektu w Jenkinsie
W rezultacie na stronie głównej panelu administracyjnego Jenkins ukaże się nasz nowy projekt:
 Lista projektów zawierająca nowo utworzony “awesome-app-ci”
Lista projektów zawierająca nowo utworzony “awesome-app-ci”
Następnie klikamy w nazwę projektu i przechodzimy do widoku zarządzania nim. Po lewej stronie widnieje kilka opcji zarządzania projektem, m. in. umożliwiająca konfigurację projektu. Klikamy więc na ikonę zębatki “Konfiguruj”. Do skonfigurowania jest kilka sekcji projektu, zaczniemy od:
Ustawienia ogólne
Wpisujemy tu prosty opis projektu. Przykład dotyczy repozytorium z Bitbucket’a, więc checkbox “Github project” pozostawiamy niezaznaczony. Warto zaznaczyć “Porzuć stare zadania”. Oznacza to, że nie będą przechowywane logi i informacje o zadaniach (pojedynczych wykonaniach projektu) starszych niż X dni lub nie będzie ich przechowywanych więcej niż Y naraz. Dzięki temu oszczędzimy miejsce na dysku, nie zapełniając go prawdopodobnie mało istotnymi informacjami o starych wykonaniach. Ciekawą opcją w tej sekcji jest “To zadanie jest sparametryzowane”, która jest przydatna np. w zadaniach wgrywających zmiany na serwer. Wówczas użytkownik przed uruchomieniem zadania może podać parametr (nazwę gałęzi, taga, hash commita itp), który powinien zostać wgrany. Tutaj pozostawiamy opcję tę niezaznaczoną.
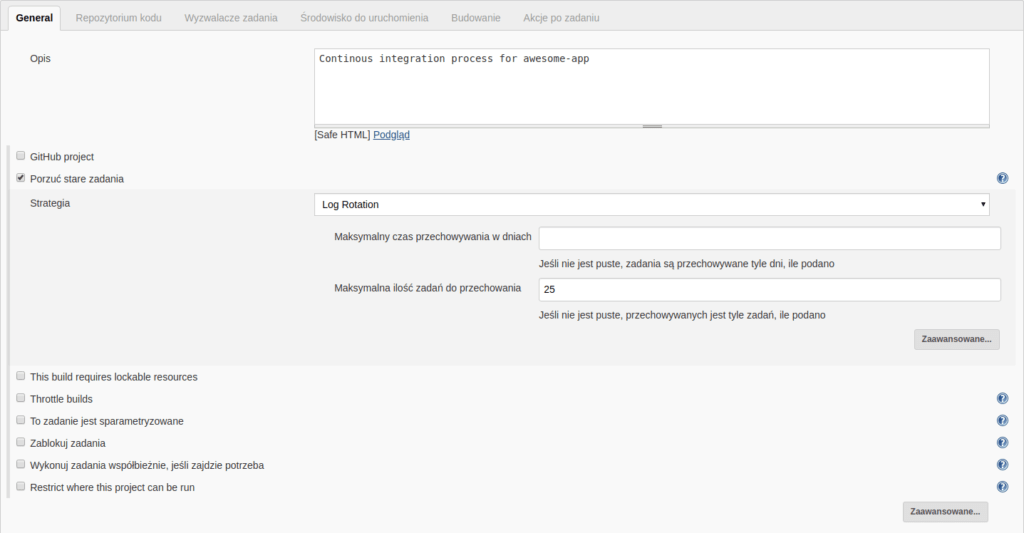 Widok sekcji “Ustawienia ogólne” konfiguracji projektu
Widok sekcji “Ustawienia ogólne” konfiguracji projektu
Wskazanie repozytorium z kodem
Następnym krokiem jest podanie informacji o adresie, pod którym znajduje się interesujące nas repozytorium kodu. W tym przykładzie, podając URL używamy zmiennych “repositoryOwner” oraz “repositoryName”, ponieważ następna sekcja wymaga ich podania. Tutaj używamy ich wartości tak, aby adres był zawsze spójny z wartościami podanymi niżej. Podajemy dostępy do repo (“Credentials”) – jest to para kluczy, którą wcześniej należy stworzyć i odpowiednio nazwać. Klucz prywatny jest widoczny tylko dla (i przechowywany na) Jenkinsie, publiczny musi zostać zgłoszony jako klucz “Read access” w odpowiednim serwisie (w tym przypadku Bitbucket). Jako “Branch specifier” podajemy wartość */${sourceBranch}. Tę wartość z kolei (nazwę gałęzi, na której należy wykonać zadanie) automatycznie dostarcza dla nas wtyczka Bitbucket Pull Request Builder , z której korzystamy w tej konfiguracji.
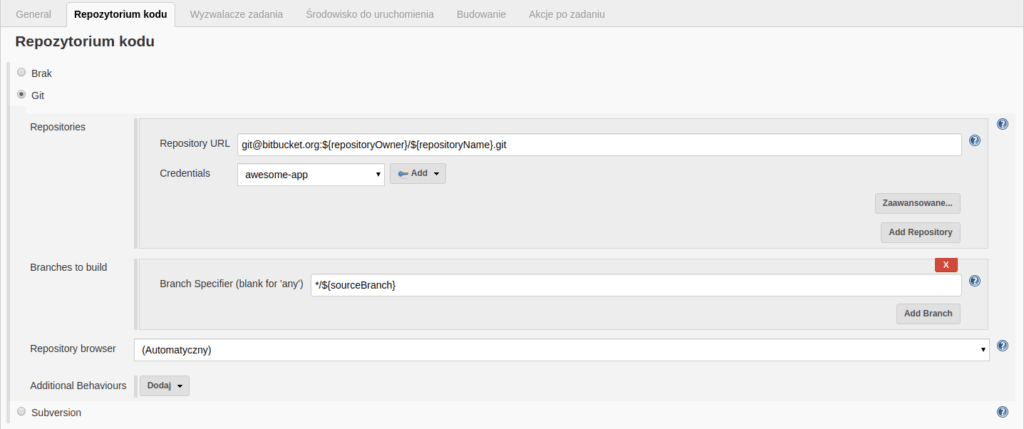 Widok sekcji “Repozytorium kodu” konfiguracji projektu
Widok sekcji “Repozytorium kodu” konfiguracji projektu
Dane dostępowe i ustawienia budowania
W tej sekcji mamy najwięcej do uzupełnienia. Zaczynamy od zaznaczenia opcji “Bitbucket Pull Requests Builder” – korzystamy z tej wtyczki w tym przykładzie. W polu “Cron” podajemy "* * * * *", co oznacza, że Jenkins będzie sprawdzał co minutę repo czy nie pojawiły się nowe zmiany wymagające uruchomienia zadania. Następne ważne pola to “Bitbucket BasicAuth Username” i “Bitbucket BasicAuth Password”, czyli nazwa i hasło użytkownika Bitbucket’a. Najlepiej stworzyć do tego dedykowanego użytkownika (w przykładzie jenkins@awesome-company.com) i dać mu dostęp do repozytorium. W polu “RepositoryOwner” podajemy organizację/użytkownika będącego właścicielem repo. Natomiast w “RepositoryName” podajemy nazwę repozytorium. W polu “CI Identifier” podajemy nazwę unikalną pośród wszystkich zadań Jenkinsa związanych z tym repozytorium – najlepiej opis tego co Jenkins robi w tym zadaniu dla tego repozytorium.
Ciekawą opcją jest tutaj “Comment phrase to trigger build”. Umożliwia ona ręczne wystartowanie zadania na Jenkinsie poprzez wpisanie odpowiedniego komentarza w pull requeście. Dla przykładu tutaj, wystarczy ładnie poprosić w komentarzu pull requestu na Bitbuckecie “test this please” a po chwili automatycznie rozpocznie się wykonanie zadania na Jenkinsie 🙂
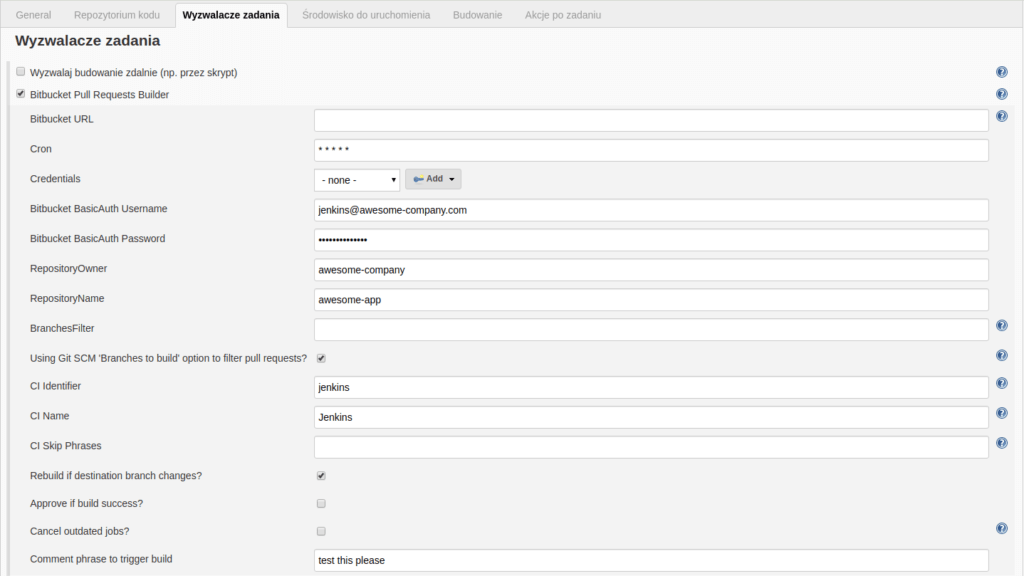 Widok sekcji “Wyzwalacze zadania” konfiguracji projektu
Widok sekcji “Wyzwalacze zadania” konfiguracji projektu
Środowisko
Tutaj ciekawą opcją jest “Delete workspace before build starts”, czyli wyczyszczenie przestrzeni, w której wykonywać się będzie zadanie, przed jego startem. (Przestrzeń jest w praktyce dedykowanym folderem na serwerze, w którym następuje przetwarzanie w ramach zadania) Pozwala to na startowanie zadań zawsze z tego samego, czystego stanu. Zwiększa to pewność wyników, które dostarcza zadanie i pewność, że są one deterministyczne, nie zależą od lokalnego stanu. Z drugiej strony, możemy kliknąć w “Zaawansowane” i kontrolować co dokładnie ma być usuwane, a co nie. I tak, jak na poniższym screenshocie, możemy czyścić przestrzeń dla każdego zadania, ale z wyjątkiem katalogu node_modules. Pozwoli to na przyspieszenie budowania, ponieważ nie będzie konieczne każdorazowe instalowanie wszystkich paczek poprzez npm.
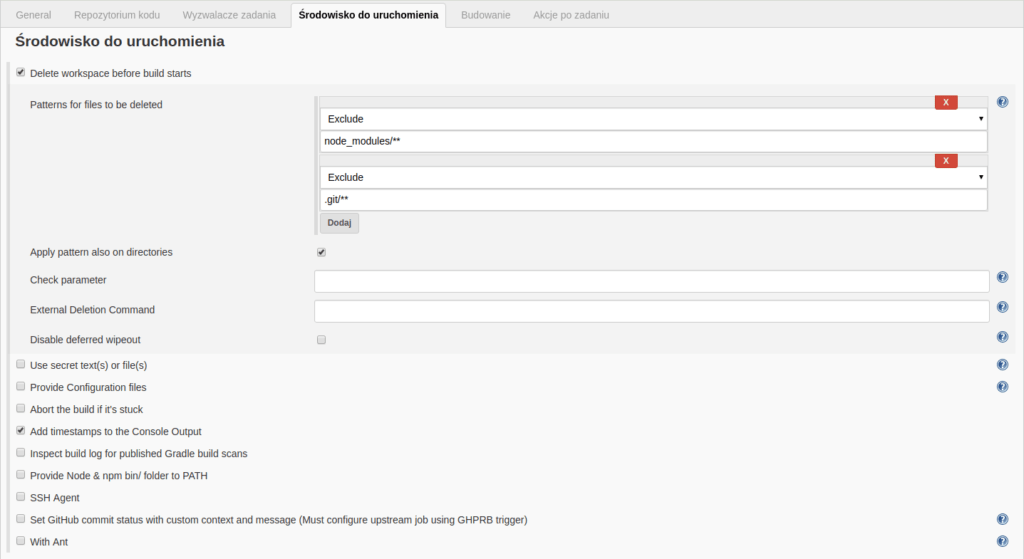 Widok sekcji “Środowisko do uruchomienia” konfiguracji projektu
Widok sekcji “Środowisko do uruchomienia” konfiguracji projektu
Budowanie
Sekcja ta umożliwia zdefiniowanie przez nas właściwych kroków (skryptu) zadania. Przykładowo, jeśli nasz projekt jest standardową aplikacją Django to prawdopodobnie chcemy:
- stworzyć nowe, lokalne, wirtualne środowisko Python (za pomocą np. virtualenv)
- aktywować to środowisko
- zainstalować wymagane paczki poprzez pip (ewentualnie także te wymagane przez npm)
- uruchomić testy z odpowiednimi ustawieniami
I to jest dokładnie to, co zrobi poniższy, przykładowy skrypt:
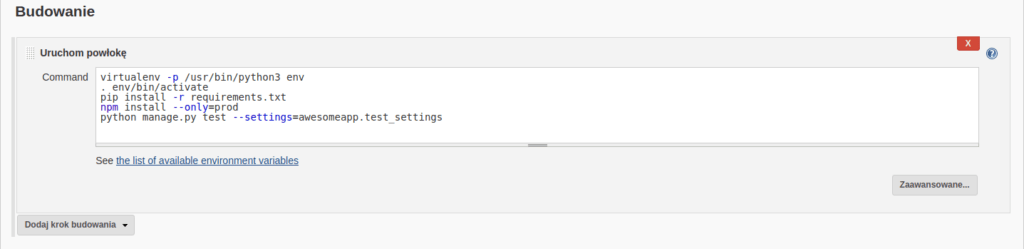 Widok sekcji “Budowanie” konfiguracji projektu
Widok sekcji “Budowanie” konfiguracji projektu
Dodatkowo, istnieje sekcja “Akcje po zadaniu”, w której możemy zdefiniować co Jenkins ma zrobić po zakończeniu wykonania zadania. Częstym przykładem tutaj jest wysyłanie maila do określonej osoby/osób w przypadku, jeśli zadanie zakończyło się niepowodzeniem. Istnieje także możliwość wysłania osobnego maila do osoby, która wprowadziła błąd.
Ciągła integracja na przykładzie projektu z GitHub’a
Konfiguracja tutaj jest w dużej części analogiczna, podam jednak w których miejscach się różni, tak, aby nie było problemu także w przypadku tego serwisu 🙂
Aby “podpiąć” repozytorium z GitHuba skorzystamy z wtyczki GitHub Pull Request Builder , analogicznej do użytej powyżej. Zacząć należy do skonfigurowania wtyczki. Można to zrobić wchodząc pod “Zarządzaj Jenkinsem” (w panelu po lewej stronie) a następnie “Konfiguracja systemu”. Odszukujemy sekcję “GitHub Pull Request Builder”. W polu “GitHub Server API URL” wpisujemy https://api.github.com. Obok pola “Credentials” klikamy “Add” i tworzymy nowy dostęp typu “User and password”, w którym wpisujemy nazwę użytkownika i hasło do konta na GitHubie. Dobrą praktyką jest stworzenie nowego konta na GH, przeznaczonego tylko dla Jenkinsa, i dodanie go jako “Collaborator” do tego repo na GH. Nie chcemy przecież używać naszych prywatnych kont, prawda?
Następnie przystępujemy do konfiguracji projektu – jest ona analogiczna do przykładu z Bitbucket’em, poza kilkoma różnicami:
- w sekcji “Ustawienia ogólne” należy zaznaczyć “GitHub project” i podać URL do projektu na GitHubie
- jako “Branch specifier” w sekcji “Repozytorium kodu” podać ${sha1} – jak zaleca dokumentacja wtyczki
- w sekcji “Wyzwalacze zadania” zaznaczyć “GitHub Pull Request Builder”, wybrać stworzone wcześniej dostępy do konta GH
- (zalecane) zaznaczyć “Use github hooks for build triggering” tak, aby Jenkins otrzymywał od GitHuba informację o konieczności uruchomienia zadania, a nie musiał samemu sprawdzać czy ma coś do roboty np. co minutę
 Podanie adresu URL repozytorium projektu w sekcji “Ustawienia ogólne”
Podanie adresu URL repozytorium projektu w sekcji “Ustawienia ogólne”
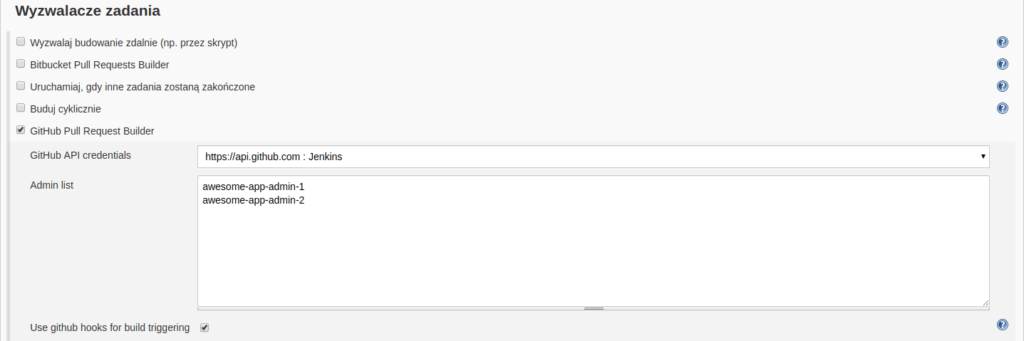 Konfiguracja wtyczki Github Pull Request Builder w sekcji “Wyzwalacze zadania”
Konfiguracja wtyczki Github Pull Request Builder w sekcji “Wyzwalacze zadania”
Ciągła integracja – podsumowanie
Jak pokazałem w tym wpisie, wdrożenie procesu ciągłej integracji nie musi być trudne i czasochłonne, przynajmniej w podstawowym zakresie. Musimy jednak pamiętać, że ciągła integracja nie nadaje się do wprowadzenia w każdym projekcie. Jeśli ten nie posiada testów lub automatycznie generowanej dokumentacji lub nie można go zbudować przy każdej zmianie to wdrożenie CI będzie niemożliwe bądź bezsensowne. Tak więc przed wdrożeniem CI produkt należy do tego odpowiednio przygotować. Sama implementacja, korzystając z jednego z dostępnych, dedykowanych rozwiązań (jakim jest bez wątpienia Jenkins), jest już potem przyjemnością 🙂
TL;DR
Jenkins umożliwia w prosty sposób “podpięcie” repozytorium kodu z GitHuba lub Bitbucketa. Śledzony jest wtedy każdy istniejący w tym repo pull request, a gdy wejdzie do niego nowa zmiana, wyzwalany jest automatycznie zdefiniowany przez nas skrypt. Może on budować aplikację, uruchamiać testy, uaktualniać dokumentację itp.